J’ai lancé le projet FineDB il y a quelques semaines. Je vais expliquer comment fonctionnent les mécanismes internes du serveur.
Pour info, le projet a un site dédié : finedb.org
Threads
Il existe 3 types de threads dans le serveur FineDB :
- Le thread principal, qui crée les autres threads puis écoute les nouvelles connexions venant des clients.
- Le thread d’écriture, dont le rôle est d’écrire dans le moteur de stockage les données qui doivent être écrites de manière asynchrone.
- Les threads de communication. Ils gèrent les échanges avec les clients, en interprétant leurs requêtes. Les lectures et les écritures synchrones sont faites directement ; les écritures asynchrones sont déléguées au thread d’écriture.
Communication entre les threads
Il y a deux flux de communication nanomsg à l’intérieur du serveur.
Le premier est un flux de type “fanout” PUSH/PULL load-balancé. Le thread principal y envoie les files descriptors correspondant aux sockets des connexions entrantes. Nanomsg distribue automatiquement ces messages aux threads de connexion, qui peuvent ainsi entamer la communication avec les clients.
Le second est un flux “fanin” SOURCE/SINK. Les threads de communication l’utilisent pour envoyer des ordres au thread d’écriture.
Schéma
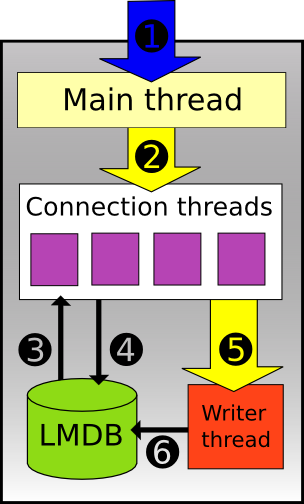
- Une socket TCP classique attend de nouvelles connexions entrantes.
- Connexion nanomsg utilisée pour transmettre les connexions entrantes aux threads de connexion.
- Les opérations de lecture sont faites directement sur le moteur de stockage.
- Les opérations d’écritures synchrones sont faites directement sur le moteur de stockage.
- Connexion nanomsg, utilisée pour transmettre les ordres d’écriture asynchrone au thread d’écriture.
- Le thread d’écriture accède directement au moteur de stockage.
État des lieux
Tout ce que j’ai décrit ci-dessus est déjà implémenté sous cette exacte forme.
Cette architecture est le fruit d’un choix. Le fait de passer par des threads qui prennent en charge les connexions entrantes est différent de la mode actuelle qui se base plutôt sur de la programmation événementielle mono-processus (à base de libevent ou libev).
Le grand avantages est une simplification importante du code, grâce à son découplage. Le thread principal écoute les nouvelles connexions, et une fois qu’elle sont établies il les envoie aux threads de connexion. Nanomsg facilite grandement cette communication, en jouant au passage les rôles de load-balancer et de file de message. Les threads de connexion ont pour seul tâche de lire les requêtes, les comprendre et les exécuter.
Il faut voir aussi que la programmation réseau mono-processus fonctionne bien tant qu’aucune opération bloquante ne peut ralentir l’ensemble des traitements. Dans le cas de FineDB, certains traitements (compression/décompression des données, accès au moteur de stockage) peuvent s’exécuter rapidement mais quand même trop lentement pour vouloir prendre le risque d’ajouter de la latence sur toutes les autres connexions.
L’inconvénient principal est que le nombre de requêtes traitées simultanément est égal au nombre de threads de connexion. Les connexions supplémentaires doivent attendre qu’une connexion se termine et que le thread devienne libre pour en prendre une nouvelle en charge.
Cet inconvénient est connu et assumé. Les threads sont très légers et un grand nombre peut être créé.
Évolutions futures
L’architecture actuelle va évoluer avec deux étapes.
La première, assez simple, consistera à gérer les connexions longues, pour les couper au bout d’un certain délai. Cela nécessitera un thread supplémentaire, qui parcourra à intervalle régulier la liste des connexions ouvertes et fermera celles qui n’ont pas montré signe d’activité depuis un certain temps.
La seconde sera plus complexe. Elle va servir à mettre en place les capacités de réplication (maître-esclave et maître-maître) de FineDB. J’en reparlerai dans un autre article, mais cela nécessitera d’ajouter encore un thread supplémentaire, qui gérera les interactions avec les autres serveurs.
Une autre piste d’amélioration serait de mixer programmation réseau événementielle et threads de traitement. Ainsi, le thread principal gérerait à lui seul les connexions ouvertes, mais confierait aux threads les opérations bloquantes. À voir si cela est nécessaire, en fonction des benchmarks que je vais mener ; cela demanderait une grosse réécriture du code.