
Le Forum PHP, c’est un événement organisé par l’Association Française des Utilisateurs de PHP le jeudi 09 et le vendredi 10 octobre 2025 en région parisienne (l’hôtel New-York du parc Disneyland Paris). L’association Temma, qui a été créée pour aider à la diffusion du framework du même nom, sponsorise l’événement. N’hésitez pas à…

Ma présentation à l’AFUP Day Lyon 2025 : Temma et PHP Way of Life
En France, nous avons deux gros rendez-vous annuels organisés par l’AFUP (Association Française des Utilisateurs de PHP) : le Forum PHP, événement national organisé sur deux jours en région parisienne au mois d’octobre, et l’AFUP Day, qui est une journée de conférences organisée dans plusieurs villes au même moment au mois…
Un site pour comparer en temps réel les offres de serveurs dédiés OVH et Dedibox
Dans un précédent article, j’ai partagé un tableau Google Sheet dans lequel je répertoriais les offres de serveurs dédiés proposées par OVH (sous les marques OVHCloud, SoYouStart et Kimsufi) et Scaleway (avec les offres Dedibox et Elastic Metal). J’espère que ce tableau a été utile à certains. Il l’a été…

Le Manifeste PHP Way of Life
Ça fait longtemps maintenant que je prône une vision du développement PHP qui utilise les bonnes pratiques de manière intelligente et mesurée, et qui repose sur quelques fondamentaux forts : À force d’expliquer mon point de vue oralement, il m’a paru plus efficace de le mettre par écrit. Je l’ai…

Le framework Temma sponsorise l’AFUP Day 2025
L’AFUP Day, c’est un événement organisé par l’Association Française des Utilisateurs de PHP le vendredi 16 mai 2025 simultanément à Lille, Lyon et Poitiers. L’association Temma, qui a été créée pour aider à la diffusion du framework du même nom, sponsorise l’événement lyonnais. Je ferai une présentation au début de…
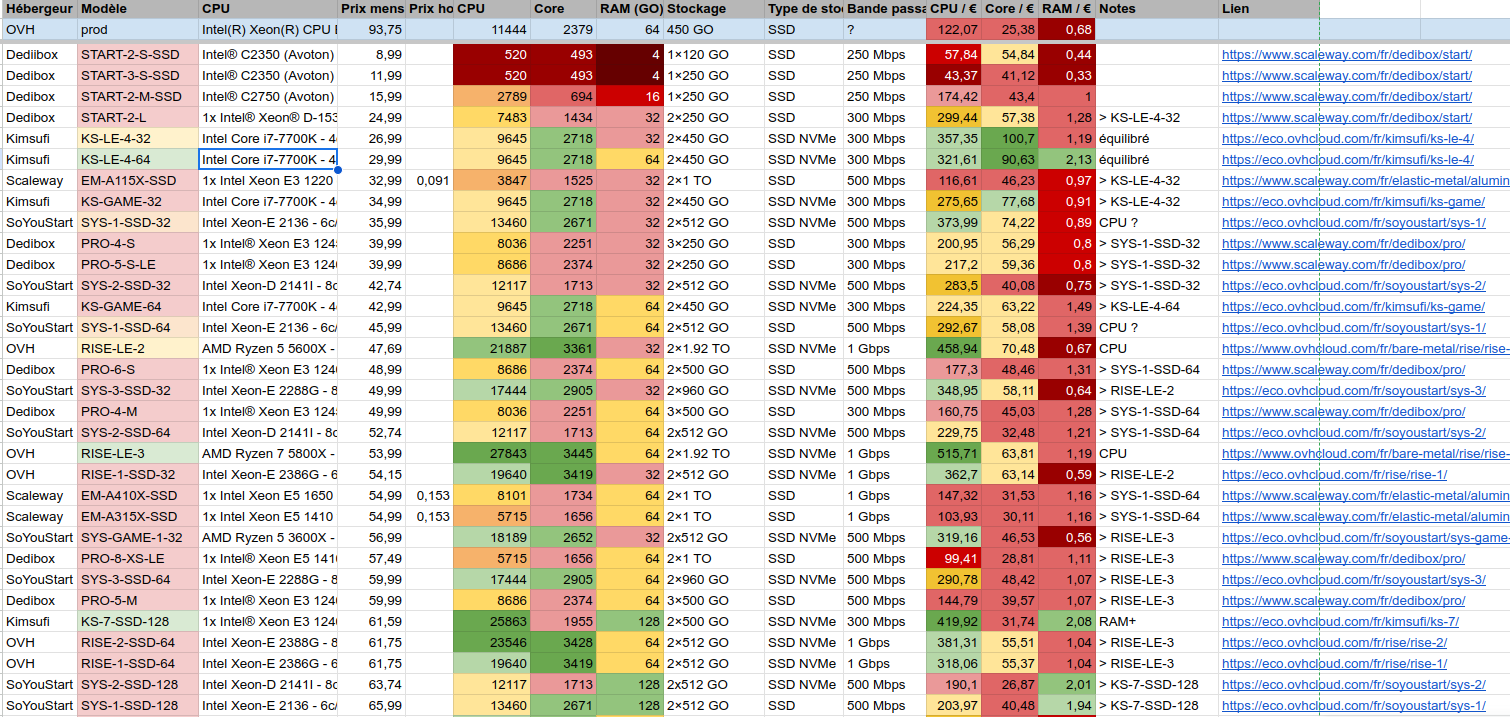
Comparatif des offres de serveurs dédiés OVH et Scaleway
Mise à jour : J’ai créé le site ServerTracker.ovh pour lister les offres OVH et Dedibox, avec les informations de disponibilité en temps réel. Plus d’infos dans cet article. Pour des besoins professionnels, j’ai créé un tableau qui liste les offres de serveurs dédiés chez OVH et Scaleway. Le but…
Créer une partition chiffrée sous Linux avec LUKS
En entreprise, il y a souvent des cas où on veut protéger des données sensibles. Le plus souvent, on archive les données dans des fichiers cryptés ; en cas de besoin, on peut décrypter ces archives pour y accéder, et en attendant on est rassuré sur le fait que personne…
Comment calculer la complexité d’un mot de passe et comment choisir un mot de passe
L’imaginaire collectif nous implante l’idée qu’un mot de passe doit être long (composé de beaucoup de caractères) et complexe (composé de beaucoup de caractères différents) pour être de bonne qualité. On va essayer de voir ce que ça représente exactement. Quelles sont les attaques sur les mots de passe ?…
Crypter un fichier sous Linux avec OpenSSL, GPG ou scrypt
Sous Linux, nous avons la chance d’avoir plusieurs outils qui peuvent être utilisés pour crypter des fichiers. Nous allons voir comment le faire avec les outils suivants : Il y a un principe que je vais appliquer dans les trois cas : la passphrase (le mot de passe) d’encryption ne…

Ma conférence sur les cycles agiles d’un mois (Forum PHP 2024)
J’ai donné aujourd’hui un « lightning talk » au Forum PHP, au sujet des cycles agiles d’un mois. J’ai déjà parlé de ces cycles sur ce blog (ici et ici), comment je les ai mis en place dans plusieurs entreprises, et comment ils ont permis d’augmenter la productivité tout en améliorant la…