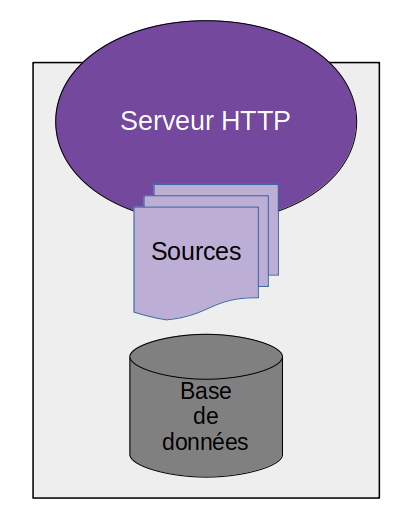
Contexte
Quand on installe une infrastructure web, on commence souvent par utiliser un unique serveur, qui fait tourner à la fois la partie applicative (serveur HTTP + code applicatif) et les bases de données.
Par la suite, on sépare habituellement ces deux parties sur des serveurs séparés.
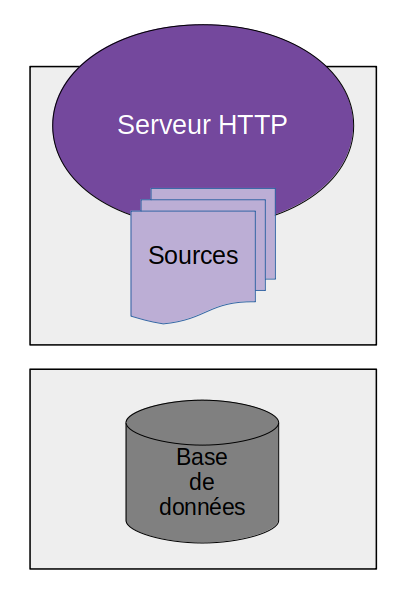
Généralement, on procède de la sorte pour des raisons de performances. Chaque machine est dédiée à une tâche, avec des ressources dédiées. Il est facile de faire évoluer l’un ou l’autre séparément, en fonction des besoins.
Incidemment, cela permet aussi − toujours pour améliorer les performances − de multiplier les serveurs frontaux.
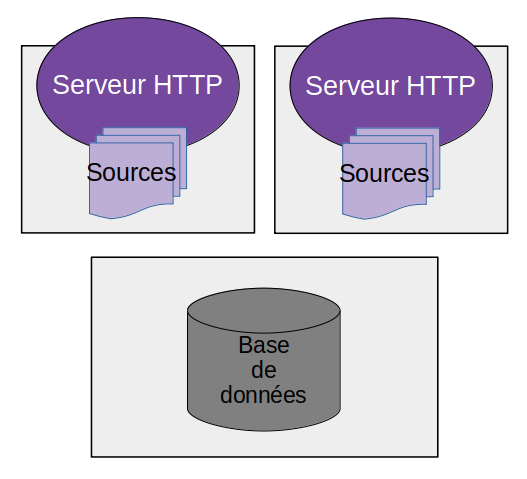
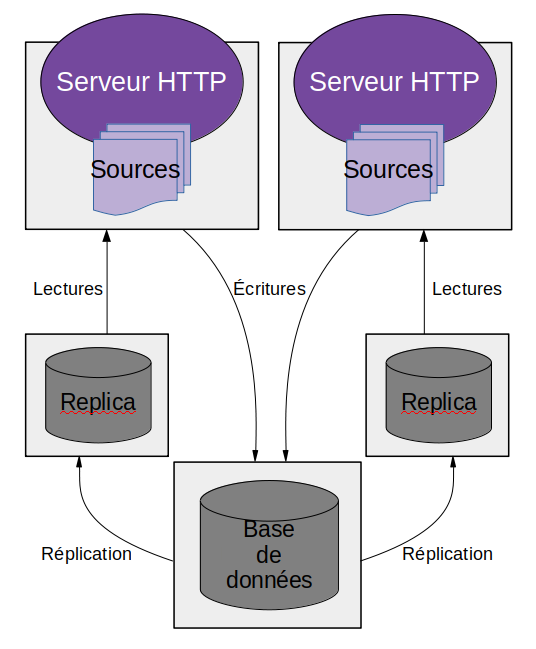
Ce n’est efficace que si l’application est gourmande en calculs ; la base de données peut rapidement devenir un goulet d’étranglement. Il est possible de contourner cela en ajoutant des serveurs de cache, ou de répliquer la base de données pour ajouter des nœuds en lecture.
Performances
Ce qu’on appelle «performances» revêt plusieurs aspects. La plupart du temps, on imagine qu’une plate-forme performante est une plate-forme qui est capable de supporter un très grand nombre d’utilisateurs simultanés. Et c’est effectivement une définition pleine de sens.
Mais pour qu’une plate-forme se retrouve à devoir gérer un très grand nombre de connexions en même temps, il faut qu’elle ait commencé par offrir un service de très haute qualité, sans quoi les utilisateurs ne seront pas au rendez-vous. On touche alors du doigt une autre facette des performances : proposer un service qui réponde le plus vite aux sollicitations des utilisateurs. Qui soit “snappy”, comme disent les anglophones.
Et pour cela, il faut que chaque requête obtienne une réponse la plus rapide possible.
On peut penser que les techniques qui permettent de soutenir un grand nombre de connexions simultanées sont aussi celles qui permettent de répondre au plus vite à chaque requête individuelle. Cela paraît logique ; si on répond très vite à une requête, on sera capable de prendre plus de requêtes en charge. Sauf que ça ne fonctionne pas comme ça.
Les connexions réseau (entre les serveurs frontaux et les serveurs de bases de données) ont un coût : elles ajoutent de la latence. La connexion de l’un à l’autre prend du temps ; faire transiter les requêtes de l’un vers l’autre, puis les réponses en sens inverse, prend du temps.
Des études montrent que l’être humain perçoit les latences à partir de 13 ms, et à partir de 75 ms on peut considérer que l’expérience utilisateur est dégradée.
Il est donc important de réduire toutes les sources de latence qui s’additionnent les unes aux autres. Évidemment, le plus gros de ces sources reste au niveau de la base de données, du traitement applicatif et de tous les éléments graphiques chargés par le navigateur ; il faut les traiter en priorité, car il ne sert à rien de vouloir économiser des poignées de millisecondes si on perd des secondes pleines sur une requête SQL inefficace ou sur des chargements d’images non optimisées.
Test
Pour réduire les latences réseau, on peut simplement tout regrouper sur une même machine. Mais le gain est vraiment tangible si on utilise des sockets Unix au lieu des sockets réseau habituelles. Ainsi, les données transitent directement à travers le kernel au lieu de traverser toutes les couches de gestion du réseau.
Pour tester l’effet, j’ai fait un petit comparatif. J’ai pris une application PHP utilisant de manière intensive deux bases de données (une Redis et une MySQL). D’un côté, je l’ai déployée sur une architecture avec deux machines virtuelles (dual CPU 3,1 GHz, 7 GO de RAM), et de l’autre côté sur une architecture avec une seule machine (dual CPU 2,3 GHz).
Sur l’architecture à deux machines, l’application se connecte évidemment par le réseau pour accéder aux données. Sur l’architecture à une seule machine, tout passe par des sockets Unix.
Pour faire simple, et même si ce test n’est pas hyper pertinent (parce que pas très rigoureux), je suis arrivé à un temps de génération brut de la page presque divisé par deux : une moyenne de 215 ms contre 410 ms.
Sur une page qui utilise moins la base de données, la différence est moins grande mais néanmoins palpable : 56 ms contre 84 ms en moyenne.
Cela est corroboré par plusieurs tests trouvés sur le web, qui indiquent que la latence des sockets Unix est 25% à 33% plus faible que celle des sockets réseau, alors que leur bande passante peut être jusqu’à deux fois plus grande (cf. ici, ici, ici, et ici).
Configuration
La configuration pour utiliser les sockets Unix est très simple.
Sous Ubuntu, MySQL est déjà configuré par défaut pour ouvrir une socket Unix en plus d’écouter sur un port réseau. Vérifiez que vous avez les lignes suivantes (ou similaires) dans le fichier /etc/mysql/mysql.conf.d/mysqld.cnf :
[mysqld_safe]
socket = /var/run/mysqld/mysqld.sock
Pour la connexion client, tout dépend du langage de programmation et de la librairie utilisée pour vous connecter au serveur. Mais la plupart du temps, il suffit de fournir “localhost” comme nom de serveur (et pas “127.0.0.1”) et le chemin vers la socket Unix dans un paramètre supplémentaire.
Pour Redis, éditez le fichier /etc/redis/redis.conf pour vérifier que les lignes suivantes (ou similaires) ne sont pas commentées :
unixsocket /var/run/redis/redis-server.sock
unixsocketperm 766
Là encore, la connexion dépend du langage et de l’objet de connexion. Mais il suffit habituellement de fournir le chemin vers la socket Unix à la place du nom de serveur.
Pour Memcache, les choses sont légèrement différentes. Au contraire de MySQL et Redis, il n’est pas capable d’écouter en même temps sur une socket Unix et une socket réseau. Il faut donc faire un choix (qui n’est pas compliqué dans notre cas, mais il faut l’avoir en tête quand on met en place une architecture serveur).
Pour que Memcache écoute sur une socket Unix, éditez le fichier /etc/memcached.conf pour ajouter les lignes suivantes :
-s /var/run/memcached/memcached.sock
-a 0766
Conclusion
De nos jours, nous avons à notre disposition des technologies qui facilitent grandement la scalabilité verticale (faire grossir le serveur quand les besoins augmentent), alors qu’il y a encore 10 ans on était obligé de passer par de la scalabilité horizontale (ajouter des serveurs supplémentaires), qui est plus délicate à mettre en œuvre − surtout si elle n’est pas prise en compte dès la conception.
Donc pour une application web qui doit faire ses preuves, pour laquelle on a tout intérêt à privilégier le confort des premiers utilisateurs plutôt que d’espérer devoir gérer une forte charge, je ne peux que vous conseiller de tout faire tenir sur un seul serveur, et de faire grossir ce serveur si vos besoins augmentent.
Au passage, on peut remarquer que d’un point de vue financier, c’est une stratégie qui tient complètement la route.
En fait, il ne s’agit que d’un exemple de l’adage disant qu’il ne faut pas optimiser prématurément.
Question bete mais : normalement, si une socket reseau se connecte en boucle locale, normalement il devrait y avoir un court-circuit pour passer la pile reseau (a priori TCP/IP) non ? Je pensais en tout cas que c’etait fait de facon transparente…
Non, c’est bien différent. Les sockets réseaux sont gérées de la même manière, qu’on soit sur une connexion locale ou distante. En tout cas, tout ce que j’ai pu lire sur le sujet allait dans ce sens, et c’est confirmé par les benchmarks.
Tu as peut-être en tête l’interface réseau « loopback » (boucle locale en français), qui n’est effectivement pas gérée de la même manière que les interfaces Ethernet ou wifi, et qui est plus efficace au niveau du kernel. Et là c’est transparent ; tu passes par cette boucle locale dès que tu tapes sur 127.0.0.1.
Oui oui, je pensais bien a loopback, que j’ai appelé boucle locale dans ma première phrase. 🙂 J’avais l’impression que si pour l’URL je disais en gros protocole://localhost tout se passait comme si j’utilisais l’interface loopback directement (et donc court-circuitage de la pile réseau).
Je demandais principalement parce que du coup, si jamais pour une raison étrange le logiciel utilisé ne prévoit rien pour les sockets UNIX explicitement, je me disais que spécifier une adresse locale via localhost devrait être une rustine correcte (mais je n’ai jamais eu à tester).
Oui je comprend, mais malheureusement non. Tu évites juste (mais c’est déjà pas mal) de passer par toutes les couches de gestion du matériel (Ethernet ou wifi) ; mais tu passeras quand même par la gestion réseau.
Pour être plus précis, il est éventuellement possible qu’en utilisant un nom (« localhost » ou « localhost.localdomain », par exemple) au lieu de l’adresse IP 127.0.0.1, tu ne passes pas par le loopback, mais que tu tombes quand même sur la machine locale. Ce sera le cas si le nom est résolu vers une adresse IP qui est gérée par une interface réseau physique. Pas de loopback dans ce cas.
@amaury En fait tout dépend du programme 🙂
Avec MySQL si tu ne forces pas le protocole TCP, localhost fait appel au socket unix et non à la stack TCP/IP sur le loopback (https://dev.mysql.com/doc/refman/8.0/en/connecting.html).
Mais pour le reste tout d’accord 🙂
Oui, oui. J’ai bien écrit «la plupart du temps, il suffit de fournir “localhost” comme nom de serveur» 🙂
« De nos jours, nous avons à notre disposition des technologies qui facilitent grandement la scalabilité verticale (faire grossir le serveur quand les besoins augmentent), alors qu’il y a encore 10 ans on était obligé de passer par de la scalabilité horizontale (ajouter des serveurs supplémentaires), qui est plus délicate à mettre en œuvre − surtout si elle n’est pas prise en compte dès la conception. »
C’est marrant, j’aurais plutôt dit qu’aujourd’hui, avec la conteneurisation sous Docker, et encore plus avec l’orchestration des conteneurs cf. Kubernetes, on pousse beaucoup plus vers l’horizontal (avoir au maximum des services stateless, etc…).
Et c’est vrai que les tous nouveaux services, ceux qui émergent aujourd’hui, tâchent justement de prendre cela en compte dès la conception.
Non ?
Oui, tu as raison, on pousse beaucoup vers la scalabilité horizontale. Parce que c’est hype (on a des technos modernes qui facilitent les choses), parce que c’est mis en avant par les fournisseurs de solutions cloud, parce que plusieurs entreprises à succès font des retours d’expérience très positifs à ce sujet. Et oui, de manière générale, la scalabilité horizontale, c’est une très bonne chose (aussi bien pour des raisons de performances que pour viser la haute disponibilité).
Sauf que, comme je le disais, c’est plus délicat à mettre en œuvre que de la scalabilité verticale, notamment parce que cela induit souvent de repenser certains bouts de l’architecture. C’est plus simple lorsque c’est pris en compte dès la début de la conception ; sauf que ça implique quand même des contraintes supplémentaires (si si, quoi qu’en disent ceux qui font des micro-services serverless, ils iraient encore plus vite en développant de manière classique).
Surtout que la scalabilité verticale bénéficie elle aussi des technos modernes. Si tu as découpé ton application avec des containers Docker, tu pourras facilement adapter la puissance des VM qui font tourner les containers en fonction de tes besoins.
Autrement dit, avant de dupliquer ton container sur plusieurs VM, tu commenceras par le faire tourner sur une VM plus puissante. C’est juste un clic de souris !
Voilà, c’était le sens de ma phrase.
Bonjour,
je suis assez d’accord avec ton analyse, je ne suis pas friand de docker et autres conteneurisations qui sont un peu un moyen de permettre aux dev de penser qu’ils sont sysadmin… 😉
Mais il y a pas mal de cas où l’on ne peut pas utiliser de socket unix parce que par exemple l’appli est chrootée (comme un serveur Postfix par exemple pour qui /var/run n’existe pas et qui du coup doit « causer » avec dovecot ou des milters via des socket réseau).
Il est vrai qu’augmenter les caractéristiques d’une VM est plus simple que de mettre en place une haute disponibilité réellement fonctionnelle. Entre les synchros MySQL qui se perdent, les haproxy qui ne « round robin » plus, la synchro des caches divers, des données de site web, on multiplie en théorie la tolérance aux pannes ou à la charge, mais ce que je constate en pratique, et ça c’est mathématique, on multiplie à coup sûr les causes de pannes.