Introduction
Depuis 2017, je gère le projet Arkiv, qui permet de sauvegarder des serveurs facilement. Il sauvegarde les fichiers/répertoires et les bases de données MySQL (avec mysqldump ou XtraBackup), avec un archivage sur Amazon S3 et Amazon Glacier. C’est un script shell assez complexe (près de 1200 lignes de code). Je l’ai créé pour mes propres besoins, et je sais qu’il est utilisé par d’autres personnes.
Petite remarque en passant, j’avais fait mon stage de fin d’études et mon début de carrière chez Arkeia, une société franco-américaine qui éditait un logiciel de sauvegarde à destination des entreprises (et qui n’existe plus aujourd’hui, après avoir été rachetée par Western Digital). Donc j’ai toujours gardé un œil sur le monde de la sauvegarde.
Une refonte plus moderne et performante d’Arkiv est en cours depuis un an et demi. J’ai donc été amené à regarder de près les solutions existantes. En dehors des solutions “traditionnelles” comme Amanda, Bacula ou Duplicati, il y a trois logiciels très intéressants qui sont apparus ces 10 dernières années : Borg, Restic et Kopia. S’y est ajouté très récemment le logiciel Plakar. Ils sont tous open-source, offrent globalement les mêmes fonctionnalités, et chacun repose sur son propre système de stockage.
Ces systèmes de stockage offrent plusieurs fonctionnalités : les fichiers sont dédupliqués (si deux fichiers sont identiques, leur contenu n’est stocké qu’une seule fois ; et en fait la déduplication opère sur des « bouts » de fichiers, pas uniquement sur les fichiers entiers), ils sont compressés et ils sont chiffrés. Chaque système repose sur des principes différents mais similaires : les algorithmes de compression et de chiffrement peuvent différer légèrement, de même que les algorithmes servant à découper les fichiers en blocs, pour effectuer la déduplication (car ils opèrent sur des blocs de taille variable, ce qui est plus efficace que de travailler sur des blocs de taille fixe).
Format d’archivage
Comme je disais plus haut, le logiciel Plakar est apparu récemment, et est encore en pleine phase de développement. On peut raisonnablement se demander ce qu’il apporte par rapport aux trois autres solutions que j’ai citées, mais nul doute que son équipe va chercher à se démarquer.
Ils communiquent sur leur moteur de stockage nommé Kloset (et là encore on peut raisonnablement se demander ce qu’il apporte par rapport à ceux de Borg, Restic et Kopia), ainsi que sur un nouveau format de fichier d’archivage − reposant sur les mêmes principes que Kloset − nommé ptar. La promesse du ptar est d’offrir toutes les fonctionnalités que le bon vieux tar n’offre pas : le chiffrement, la compression, la déduplication, la vérification d’intégrité, la capacité à extraire un fichier sans décompresser/décrypter l’archive complète, etc.
Il faut savoir que des formats d’archivage, il en existe déjà un certain nombre (63 formats listés sur Wikipédia). À commencer par le ZPAQ et le DAR, qui offrent une bonne partie des fonctionnalités du ptar. Et vous savez ce que c’est lorsqu’un nouveau format apparaît, on pense immédiatement à cette image de xkcd :

Je me suis donc demandé si on pouvait utiliser les outils Unix standards pour créer un format d’archivage plus élaboré que le tar habituel, sans pour autant avoir besoin d’installer de nouveaux logiciels. L’idée n’est évidemment pas d’atteindre les mêmes résultats que tous les autres logiciels que j’ai cités, mais de voir jusqu’où on peut aller dans cette direction.
Le but, c’est d’avoir un format facilement exploitable sur n’importe quel système possédant les outils de base, sans avoir besoin d’installer des logiciels complémentaires. Parce que si on se place dans la situation où vous devez restaurer des données en urgence, et que vous n’avez entre les mains qu’un fichier ZPAQ, DAR ou PTAR, votre niveau de stress va sûrement crever le plafond.
Les fonctionnalités voulues pourraient être :
- Pouvoir créer une archive en y mettant des fichiers ou des répertoires (c’est bien le minimum, hein).
- Que les fichiers soient compressés et chiffrés.
- Qu’il soit possible d’extraire un fichier sans avoir besoin de décompresser et décrypter l’archive entière.
- Qu’à l’extraction d’un fichier, son intégrité soit vérifiée, afin d’être sûr qu’il n’a pas été altéré.
- Qu’il y ait une déduplication sur les fichiers complets (une déduplication à base de blocs serait trop complexe, on va juste gérer le cas des fichiers dupliqués en entier).
- Pour des raisons de sécurité et de confidentialité, il ne doit pas être possible d’accéder aux noms des fichiers sans avoir la clé de déchiffrement.
- Pour se faciliter la vie, on peut dire que le fichier doit être immuable (“immutable” en anglais). C’est une caractéristique mise en avant pour le format ptar, mais c’est surtout beaucoup plus simple à implémenter.
Préambule technique
La contrainte de base est d’utiliser uniquement des outils standards :
- tar permet de regrouper plusieurs fichiers dans une archive, en enregistrant leurs méta-données (type de fichier, date de modification, propriétaire et groupe, droits d’accès).
- zstd est un logiciel de compression incroyablement plus rapide que les autres (zip, gzip, 7zip, bzip2, xz). Il permet aussi de vérifier l’intégrité du fichier compressé.
- openssl permet notamment de chiffrer un fichier, ou encore d’en calculer une signature (un hash en anglais).
- grep, cut , cat, tr, printf permettent de manipuler les fichiers textuels et les chaînes de caractères.
- mkdir, mktemp, mkfifo, chmod, chown, touch permettent de manipuler les arborescences de fichiers.
Toutes les opérations doivent pouvoir se faire avec un simple shell POSIX.
On aura besoin de créer des signatures (des “hash”). Je choisis d’utiliser l’algorithme SHA-512/256, qui utilise les mêmes calculs que SHA-512, mais dont le résultat est tronqué pour tenir sur 32 bits. Il présente plusieurs avantages : il est aussi compact que le SHA-256, mais est aussi rapide que le SHA-512 sur les systèmes 64 bits (en fait, il est même un peu plus rapide ; environ 45% plus rapide que SHA-256, et 25% plus rapide que SHA-512). Le calcul de signature se fait avec openssl.
Pour le chiffrement des fichiers, on utilisera l’algorithme AES-256-CBC, en utilisant aussi openssl (comme je l’expliquais dans un précédent article). C’est un algorithme de chiffrement symétrique, donc le même mot de passe sera utilisé pour chiffrer et déchiffrer les données.
Design technique
L’idée est que l’on va calculer des signatures pour chaque fichier à archiver. Ces signatures vont être utilisées pour identifier chaque contenu, et on va les références dans un fichier d’index.
Pour chaque fichier enregistré dans l’archive, on va lister son nom dans l’index, et on va y associer la signature de son contenu. Ainsi, si deux fichiers contiennent les mêmes données, l’index associera la même signature de contenu pour chaque nom de fichier.
À côté de ça, on va vouloir stocker les méta-données associées à chaque fichier.
Et pour se faciliter la vie, on va utiliser le format tar pour stocker ces méta-données. Comme vous le savez, lorsqu’on extrait un fichier d’une archive tar, il récupère toutes ses caractéristiques (propriétaire, groupe, droits d’accès, date de modification).
Dans le cas d’un lien symbolique ou d’une FIFO, on va faire un tar direct du fichier. Dans le cas d’un fichier régulier, on va créer un fichier vide auquel on va donner les mêmes caractéristiques que le fichier source, et on va créer un tar à partir de ce fichier vide (qu’on effacera ensuite). Ainsi, on aura sauvegardé les informations nécessaires pour recréer le fichier.
Pour qu’il ne soit pas possible de trouver les noms des fichiers stockés grâce à un dictionnaire, on concaténera un préfixe (déterminé aléatoirement) au début de toutes les chaînes pour lesquelles on calculera une signature. Ce préfixe sera stocké dans l’archive.
L’archive complète va être stockée dans un fichier tar basique, non chiffré et non compressé. Pas de stress, c’est normal, ce sont les éléments à l’intérieur qui le seront.
En fait, ce fichier tar peut être vu comme un répertoire dont l’arborescence contiendrait les éléments suivants :
magic.zst: fichier permettant de vérifier qu’il s’agit bien d’une archive au format Arkiv, contenant le numéro de version du format.prefix.zst.aes: fichier contenant une chaîne aléatoire qui doit être ajoutée au début de toutes les données pour lesquelles ont créera une signature.index.zst.aes: le fichier d’index, qui fait correspondre les noms des fichiers avec les signatures de leurs contenus.meta/: sous-répertoire contenant les fichiers de méta-données (fichiers tar, compressés et chiffrés), dont les noms sont les signatures des noms des fichiers archivés.data/: sous-répertoire contenant les fichiers binaires (les contenus des fichiers archivés), compressés et chiffrés, nommés avec la signature du contenu.
Pour le voir sous forme graphique :
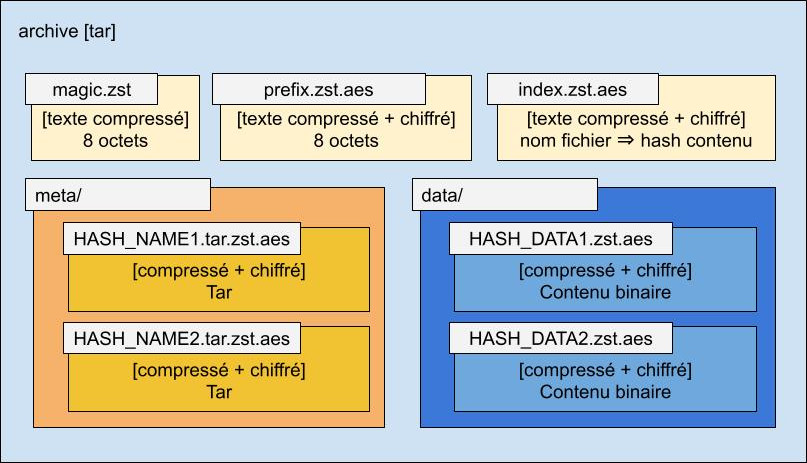
Fichier magic.zst
Ce fichier sert à vérifier qu’il s’agit bien d’une archive au format Arkiv, et contient le numéro de version.
Pour le moment, il contiendra simplement la chaîne arkiv001.
Le fichier est compressé, afin de pouvoir vérifier son intégrité avec zstd.
Fichier prefix.zst.aes
Fichier contenant 8 octets générés aléatoirement. Le but est d’ajouter 64 bits d’entropie à tous les calculs de signatures SHA-512/256.
Ces octets pourraient être générés avec la commande : head -c 8 /dev/urandom
Mais pour être portable sur tous les systèmes Unix, on utilisera plutôt : openssl rand 8
Le fichier est chiffré.
Pour simplifier les traitements, le fichier contient 8 octets binaires (au sens que ce ne sont pas des caractères valides dans un texte UTF-8, il peuvent par exemple contenir des octets nuls), c’est la version encodée en base 64 qui sera utilisée comme préfixe lorsqu’on va calculer les signatures.
Fichier index.zst.aes
C’est un fichier texte très simple. Il liste tous les fichiers enregistrés dans l’archive, en leur associant la signature de leurs contenus (pour les répertoires, les liens symboliques et les FIFO, l’index liste le nom de l’élément, sans y associer de signature de contenu).
Le fichier est compressé et chiffré.
Ce fichier permet de retrouver le fichier de contenu à partir du nom d’un fichier. Il permet aussi de lister tous les fichiers présents dans l’archive.
Les fichiers réguliers sont listés de la forme : "chemin fichier"=HASH_contenu
Les fichiers spéciaux sont listés de la forme : "chemin fichier"
Exemple :
"/etc/cron.d"
"/etc/cron.hourly/logrotation"=7f…21
"/etc/mtab"
"/home/user/save/logrotation"=7f…21Langage du code : JavaScript (javascript)Ce fichier contient les informations suivantes :
- On a sauvegardé le répertoire
/etc/cron.d(et tout son contenu). En calculant la signature du nom du répertoire, on obtientab…92, donc les méta-données seront stockées dans le fichiermeta/ab…92.tar.zst.aes. Comme c’est un répertoire, il n’y a pas besoin de fichier dans le répertoiredata/. - On a sauvegardé le fichier
/etc/cron.hourly/logrotation. Les méta-données sont dans le fichiermeta/78…01.tar.zst.aes, et les données dansdata/7f…21.zst.aes. - On a sauvegardé le fichier
/etc/mtab, qui est un lien symbolique. Les méta-données sont dans le fichiermeta/8f…52.tar.zst.aes. Comme c’est un lien symbolique, il n’y a pas besoin de fichier dans le répertoiredata/. - On a sauvegardé le fichier
/home/user/save/cronrotation, dont le contenu est exactement le même que celui du fichier/etc/cron.hourly/logrotation. Les méta-données sont dans le fichiermeta/2b…b8.tar.zst.aes. Et c’est donc aussi le fichierdata/7f…21.zst.aesqui contient ses données.
Répertoire meta/
Ce répertoire contient des fichiers de méta-données, qui permettent de recréer les fichiers lors de la restauration de données.
Ces fichiers sont compressés et chiffrés.
Ils sont compressés parce que même un fichier tar minimal se compresse très bien (moins de 100 octets pour un fichier tar initial de 10 KO environ), et pour pouvoir valider leur intégrité avec zstd.
Ils sont chiffrés pour garantir la confidentialité des noms des fichiers archivés.
Ils sont nommés avec les signatures calculées à partir des noms des fichiers archivés, là encore pour des raisons de confidentialité.
Comme expliqué plus haut, ce sont des fichiers tar :
- Si le fichier source était un répertoire, un lien symbolique ou une FIFO, le tar est généré à partir du fichier source.
- Si le fichier source était un fichier régulier, le tar est généré à partir d’un fichier vide auquel on aura donné les mêmes caractéristiques (droits d’accès, propriétaire, date de modification, etc.) que le fichier source.
Répertoire data/
Ce répertoire contient les fichiers de contenu, dont le nom est égal à la signature calculée sur les données elles-mêmes.
Ces fichiers sont compressés et chiffrés.
Ils sont chiffrés pour garantir la confidentialité des données archivées.
Ils sont compressés pour diminuer leur poids, et pour pouvoir valider leur intégrité avec zstd.
Code source
Le code est quand même assez conséquent. Vous pourrez le retrouver sur le repository GitHub que j’ai créé pour l’occasion : https://github.com/Amaury/arkiv-format
Il y a deux implémentations proposées, une en shell, l’autre en Go.
Implémentation Shell
Le code fourni est écrit en shell POSIX, qui devrait normalement fonctionner sur tous les systèmes Unix (Linux, FreeBSD, NetBSD, OpenBSD, Dragonfly, macOS, AIX, Solaris), et avec n’importe quel shell (bash, ash, zsh, tcsh, ksh…). Ce code se veut solide, avec des vérifications et la gestion de cas d’erreur spécifiques (comme la réception de signaux d’arrêt, par exemple).
Commande arkiv-create
La création d’une archive se fait avec la commande arkiv-create, en donnant le nom de l’archive à créer, ainsi que les chemins des éléments (fichiers, répertoires, liens symboliques, FIFO) à y ajouter. Lorsqu’un répertoire est donné en entrée, il est parcouru et tout son contenu est ajouté récursivement.
Voici un exemple dans lequel on crée une archive nommée archive.arkiv, et qui va contenir le fichier fichier1.txt, le fichier fichier2.txt, ainsi que le répertoire /etc et tout son contenu :
$ arkiv-create archive.arkiv fichier1.txt fichier2.jpg /etcLangage du code : Shell Session (shell)À savoir : lors de la création de l’archive, un répertoire temporaire est créé ; il contient toutes les données avant qu’un tar soit fait à la fin pour générer l’archive, puis il est effacé.
Commande arkiv-ls
Pour afficher la liste des éléments stockés dans une archive, on utilise la commande arkiv-ls. Elle prend en paramètre le chemin vers l’archive. Un second paramètre optionnel peut contenir un préfixe de chemin pour les fichiers à afficher.
$ arkiv-ls archive.arkiv # affiche tous les fichiers de l'archive
$ arkiv-ls archive.arkiv /etc/cron.d # affiche l'arborescence sous /etc/cron.dLangage du code : Shell Session (shell)Commande arkiv-extract
Pour extraire un élément, on utilise la commande arkiv-extract, en lui spécifiant le chemin vers l’archive, le chemin local vers lequel faire la restauration et (optionnellement) le nom de l’élément − ou des éléments − à restaurer. Si le troisième paramètre n’est pas spécifié, tout le contenu de l’archive est extrait.
Voici un exemple d’extraction, dans lequel on va extraire le fichier /etc/hosts de l’archive archive.arkiv, et on va l’enregistrer dans le répertoire /home/user/save :
$ arkiv-extract archive.arkiv /home/user/save /etc/hostsLangage du code : Shell Session (shell)Si l’élément est un répertoire, tout son contenu est restauré en même temps.
Implémentation Go
Le code Go a été testé avec la version 1.23 du langage. Pour le compiler sur l’architecture locale, il suffit de taper (depuis le répertoire go) :
$ make init
$ make arkiv-formatLangage du code : Shell Session (shell)Pour faire de la cross-compilation, il suffit de taper :
$ make distLangage du code : Shell Session (shell)Cette commande lance la compilation sur une majorité des plateformes cibles du Go : Linux (x86 32/64, ARM 32/64, RISC-V 64, PowerPC 64 LE/BE, MIPS 32/64 LE/BE, Loong 64, IBM S/390), macOS (x86 64, ARM 64), FreeBSD (x86 32/64, ARM 32/64, RISC-V 64), NetBSD (x86 32/64, ARM 32/64), OpenBSD (x86 32/64, ARM 32/64, RISC-V 64, PowerPC 64), DragonFly BSD (x86 64), Solaris (x86 64), Illumos (x86 64), AIX (PowerPC 64), Plan9 (x86 32/64, ARM 32), Windows (x86 32/64, ARM 32/64).
Les seules plateformes pour lesquelles il n’y a pas de compilation prévue sont Android, iOS et le WebAssembly. Il faut quand même remarquer que Plan9, Windows, Solaris, Illumos (ex-OpenSolaris) et AIX ne sont pas compatibles POSIX ou ne supportent pas les fichiers de type FIFO.
Contrairement aux trois scripts shell, il n’y a qu’un seul programme arkiv-format, qui prend en premier paramètre la commande à effectuer (create, ls, create). Les paramètres suivants sont les mêmes que les scripts shell correspondants.
Exemple de création d’archive :
$ arkiv-format create archive.arkiv fichier1.txt fichier2.jpg /etcLangage du code : Shell Session (shell)Exemple de listage du contenu d’une archive :
$ arkiv-format ls archive.arkivLangage du code : Shell Session (shell)Exemple d’extraction de fichiers d’une archive :
$ arkiv-extract archive.arkiv /home/user/save /etc/hostsLangage du code : Shell Session (shell)Traitement manuel des archives
Imaginons que vous ayez à extraire des fichiers d’une archive Arkiv, sans avoir les outils spécifiques sous la main. On est justement dans le cas de figure où la compatibilité prend tout son sens.
(on va prendre le cas d’un système Linux classique, avec les outils GNU habituels)
On va définir une variable d’environnement qui contient le mot de passe de déchiffrement :
$ export ARKIV_PASS="mot de passe"Langage du code : Shell Session (shell)Pour lister tous les éléments (fichiers, répertoires, liens symboliques et FIFO) enregistrés dans une archive, on va se contenter de récupérer le fichier d’index et d’afficher les noms de fichiers qu’il contient :
# affichage des éléments contenus dans l'archive :
# extraction du fichier 'index.zst.aes' depuis l'archive
# + déchiffrement + décompression + substitution
$ tar xOf archive.arkiv index.zst.aes \
| openssl enc -d -aes-256-cbc -pbkdf2 -md sha256 -pass env:ARKIV_PASS \
| zstd -q -d -c \
| sed -E 's/^"([^"]*)".*/\1/'Langage du code : Shell Session (shell)Imaginons qu’on veuille extraire un fichier nommé fichier.txt (pour un répertoire, un lien symbolique ou une FIFO c’est un peu différent, je vous invite à aller lire le code ; mais les principes de base sont les mêmes).
Pour commencer, on récupérer le fichier d’index, puis on va chercher dedans la ligne qui commence par "fichier1.txt"=, car on trouvera ensuite la signature correspond au fichier de données.
Une fois qu’on a récupéré cette signature, on peut facilement récupérer le fichier qui contient les données.
# récupération du hash de données :
# extraction du fichier 'index.zst.aes' depuis l’archive
# + déchiffrement + décompression + récupération du hash de données
$ HASH_DATA="$(tar xOf archive.arkiv index.zst.aes \
| openssl enc -d -aes-256-cbc -pbkdf2 -md sha256 -pass env:ARKIV_PASS \
| zstd -q -d -c \
| grep '"fichier.txt"=' \
| cut -d'=' -f2)"
# récupération du fichier de données :
# extraction du fichier 'data/$HASH_DATA.zst.aes' depuis l’archive
# + déchiffrement + décompression
$ tar xOf archive.arkiv "data/$HASH_DATA.zst.aes" \
| openssl enc -d -aes-256-cbc -pbkdf2 -md sha256 -pass env:ARKIV_PASS \
| zstd -d -o "fichier.txt"Langage du code : Shell Session (shell)Si vous souhaitiez restaurer le fichier avec les mêmes caractéristiques (propriétaire, groupe, droits d’accès, date de modification), il faut effectuer des actions supplémentaires après celles décrites juste au-dessus.
On va commencer par récupérer le préfixe stocké dans prefix.aes, l’encoder en base 64, puis l’utiliser pour calculer la signature à partir du nom du fichier. Grâce à cette signature, on pourra récupérer le fichier de méta-données, et enfin utiliser ce dernier pour mettre à jour le fichier précédemment extrait.
# récupération du préfixe :
# extraction du fichier 'prefix.zst.aes' depuis l’archive
# + déchiffrement + encodage en base 64
$ PREFIX="$(tar xOf archive.arkiv prefix.zst.aes \
| openssl enc -d -aes-256-cbc -pbkdf2 -md sha256 -pass env:ARKIV_PASS \
| zstd -q -d -c \
| openssl base64 -A)"
# calcul de la signature du nom du fichier, en ajoutant le préfixe au début
$ HASH_NAME="$(printf "%s%s" "$PREFIX" "fichier.txt" | openssl dgst -r -sha512-256 | cut -d' ' -f1)"
# récupération du fichier de méta-données (sous le nom
# 'fichier.txt.meta/fichier.txt') :
# extraction du fichier 'meta/$HASH_NAME.tar.zst.aes' depuis l’archive
# + déchiffrement + décompression
$ mkdir -p fichier.txt.meta
$ tar xOf archive.arkiv "meta/$HASH_NAME.tar.zst.aes" \
| openssl enc -d -aes-256-cbc -pbkdf2 -md sha256 -pass env:ARKIV_PASS \
| zstd -q -d -c \
| tar -xpf - "fichier.txt" -C fichier.txt.meta
$ META_PATH="fichier.txt.meta/fichier.txt"
# récupération des méta-données
$ MODE="$(stat -c '%a' "$META_PATH" 2>/dev/null || echo 0644)"
$ UID="$(stat -c '%u' "$META_PATH" 2>/dev/null || echo 0)"
$ GID="$(stat -c '%g' "$META_PATH" 2>/dev/null || echo 0)"
$ MTIME="$(stat -c '%Y' "$META_PATH" 2>/dev/null || date +%s)"
$ TIMESTAMP="$(date -d "@$MTIME" "+%Y%m%d%H%M.%S")"
# modification des droits, propriétaire/groupe et date du fichier extrait
$ chmod "$MODE" "fichier.txt"
$ chown "$UID:$GID" "fichier.txt" # peut échouer si on n'est pas root
$ touch -t "$TIMESTAMP" "fichier.txt"
# suppression du fichier temporaire
$ rm -rf "fichier.txt.meta"Langage du code : Shell Session (shell)Conclusion
L’étude de ce format de fichier (et le code qui va avec) n’est qu’une expérimentation technique.
Est-ce que j’utiliserai ce format pour les archives générées par le logiciel Arkiv ? Non, et je vous explique pourquoi.
Pour commencer, l’exercice intellectuel est intéressant, mais l’aspect pratique est important. Avoir un format d’archive plus puissant que tar est séduisant, mais le fait d’avoir à utiliser de nouveaux outils est pénible. Même si le format Arkiv est pensé pour pouvoir être manipulé avec des outils Unix standards, ce n’est quand même pas si simple, surtout quand on imagine le cas d’usage où on doit restaurer des données en urgence.
Ensuite, le logiciel Arkiv sert à sauvegarder des serveurs. Cela concerne donc souvent quelques chemins contenant des fichiers de configuration (comme “/etc”), des fichiers applicatifs, et des exports de bases de données. Quand Arkiv s’exécute, il ne crée pas une archive unique contenant l’ensemble des fichiers archivés ; il crée un fichier tar par arborescence sauvegardée (et par base de données), ce qui fait qu’il y a rarement des redondances dans les fichiers archivés (qui gagneraient à être dédupliqués), et encore plus rarement un besoin impérieux d’extraire un seul fichier depuis une archive. La plupart du temps, on va restaurer une arborescence complète (donc un fichier tar parmi tous ceux créés lors d’une sauvegarde), parce qu’elle renferme des fichiers qui forment une unité assez indissociable.
Alors est-ce un problème que chaque sauvegarde génère plusieurs fichiers tar plutôt qu’un seul gros fichier ? Eh bien non, absolument pas, au contraire. Au quotidien, il est bien plus facile de gérer des fichiers plus petits ; c’est plus simple pour les copier d’un serveur à un autre, ou d’un serveur à un stockage cloud (et inversement).
Lorsque je fais des sauvegardes de bases de données, je préfère manipuler plusieurs fichiers pesant plusieurs centaines de mégaoctets chacun, plutôt qu’un énorme fichier de plusieurs dizaines ou centaines de gigaoctets. Si j’ai besoin de restaurer une base, ce sera plus rapide et pratique de récupérer un seul fichier de taille raisonnable, plutôt que de rapatrier l’énorme archive complète (sûrement de Amazon S3), pour ensuite extraire juste le fichier dont j’ai besoin depuis cette archive.
Et plus les sauvegardes sont volumineuses, plus cette logique est valable. Si mes sauvegardes de bases de données pesaient chacun plusieurs centaines de gigaoctets, je voudrais encore moins les rassembler en une seule archive qui pourrait faire plusieurs téraoctets !