Je prépare actuellement la conférence que je donnerai à l’AFUP Day au mois de mai, et dont le titre sera “Repenser les APIs”. Dans les différents points que je vais aborder, il y a la “négociation de contenu”, qu’on appelle en anglais “content negociation”, “dual-purpose endpoint” ou encore “API mode…
CSRF : Temma vs Laravel vs Symfony
J’ai déjà parlé sur ce blog des failles de sécurité de type CSRF (Cross-Site Request Forgery) : dans cet article et suite à ma conférence sur la sécurité dans les développements web. En évitant de répéter ce que j’ai déjà écrit, je vais passer en revue trois techniques qui permettent…
µCSS : un framework CSS complet, moderne et léger
Bootstrap Depuis plus d’une douzaine d’années, j’utilise le framework CSS Bootstrap pour faire la partie graphique de mes sites web. Au début, j’ai utilisé Bootstrap “pur”, mais je suis vite passé aux thèmes gratuits et payants. Passer par un thème permet d’avoir un aspect très différent du Bootstrap de base,…

µJS : rendre un site web dynamique sans framework front
Je viens de lancer le projet µJS, et je vais vous en expliquer le genèse, l’utilité, et en quoi il se distingue des outils équivalents déjà existants. Petit retour en arrière En 2017, j’avais créé la startup Skriv, qui développait un logiciel de gestion de projets qui se voulait innovant…
Utilisation de systemd pour faire tourner des workers
Dans l’un de mes précédents articles, j’expliquais comment utiliser Supervisor pour lancer des workers. L’idée était de présenter comment avoir des programmes qui s’exécutent en tâche de fond, avec un mécanisme pour les relancer automatiquement en cas de plantage. J’apprécie Supervisor parce que ses fichiers de configuration sont vraiment simples…
De PHP 8.0 à PHP 8.5, retour sur cinq ans d’innovation
Il y a quatre ans, j’ai écrit un article intitulé “De PHP 7 à PHP 8, retour sur cinq ans d’innovation”. Alors que PHP 8.5 va sortir à la fin de l’année, et que les deux dernières versions d’Ubuntu (la 25.04 et la 25.10) intègrent PHP 8.4, c’est le bon…
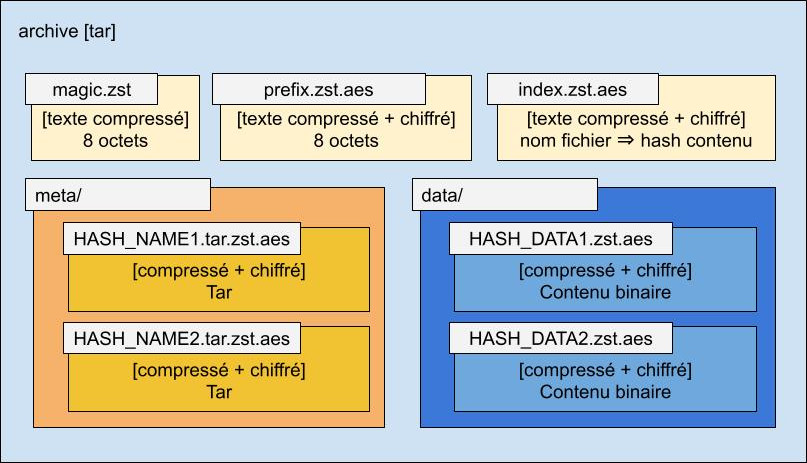
Créer un format d’archivage dédupliqué, chiffré et compressé, compatible avec les outils Unix standards
Introduction Depuis 2017, je gère le projet Arkiv, qui permet de sauvegarder des serveurs facilement. Il sauvegarde les fichiers/répertoires et les bases de données MySQL (avec mysqldump ou XtraBackup), avec un archivage sur Amazon S3 et Amazon Glacier. C’est un script shell assez complexe (près de 1200 lignes de code).…
Un site pour comparer en temps réel les offres de serveurs dédiés OVH et Dedibox
Dans un précédent article, j’ai partagé un tableau Google Sheet dans lequel je répertoriais les offres de serveurs dédiés proposées par OVH (sous les marques OVHCloud, SoYouStart et Kimsufi) et Scaleway (avec les offres Dedibox et Elastic Metal). J’espère que ce tableau a été utile à certains. Il l’a été…

Le Manifeste PHP Way of Life
Ça fait longtemps maintenant que je prône une vision du développement PHP qui utilise les bonnes pratiques de manière intelligente et mesurée, et qui repose sur quelques fondamentaux forts : À force d’expliquer mon point de vue oralement, il m’a paru plus efficace de le mettre par écrit. Je l’ai…
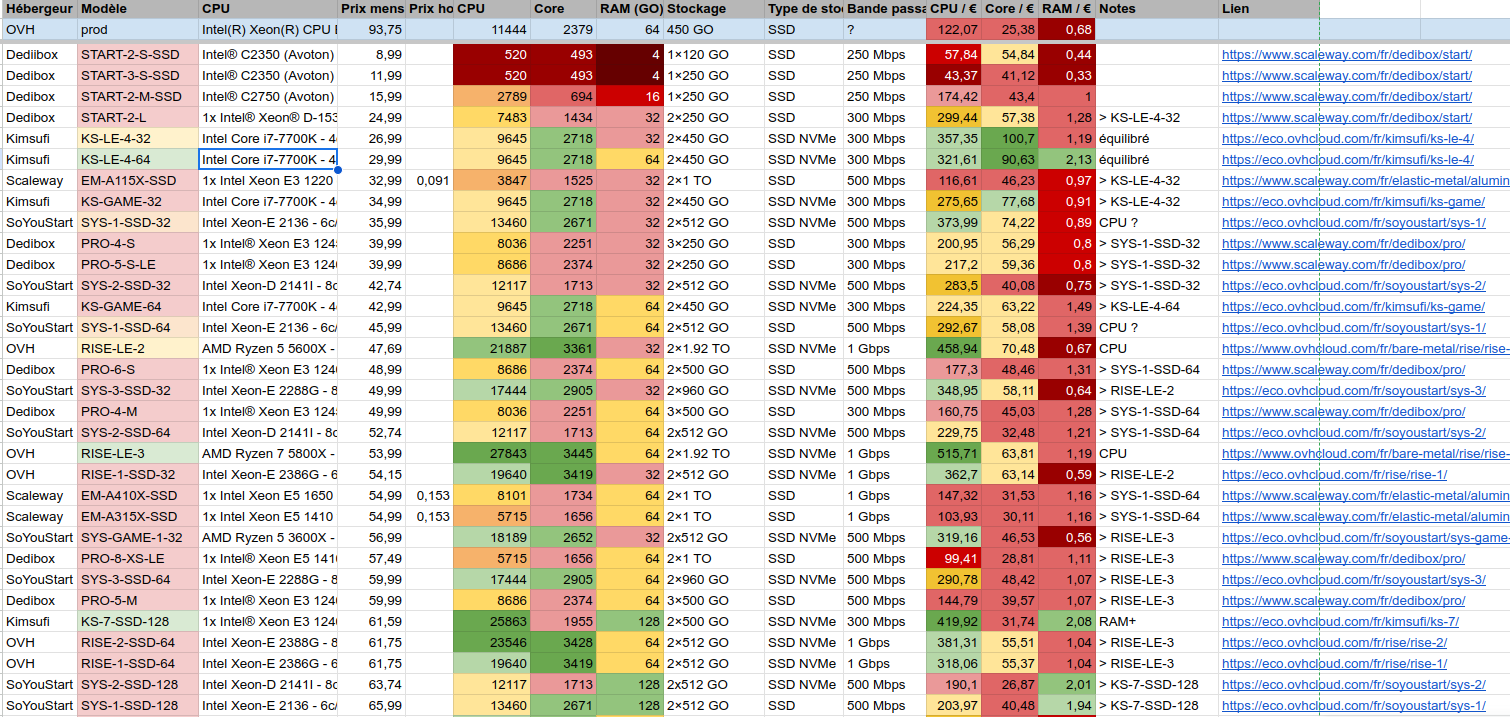
Comparatif des offres de serveurs dédiés OVH et Scaleway
Mise à jour : J’ai créé le site ServerTracker.ovh pour lister les offres OVH et Dedibox, avec les informations de disponibilité en temps réel. Plus d’infos dans cet article. Pour des besoins professionnels, j’ai créé un tableau qui liste les offres de serveurs dédiés chez OVH et Scaleway. Le but…